Welcome to Deutsche Telekom’s innovation
program on Artificial Intelligence.
We love ai
Join our next ONLINE EVENT on September 29

36
days
23
hours
12
minutes
44
seconds

WHO WE ARE
One Conversation
We are ‘One Conversation’, an innovation program at Deutsche Telekom – creating
personalized customer interactions with Artificial Intelligence (AI).

OUR MISSION
Let’s humanize AI
We are improving our customers' experience and taking efficiency in service delivery
to a new level – by using human-centric technology along the customer lifecycle.

Our vision
One rewarding and coherent conversation
We empower our customers to deliver a more individualised, controllable interaction
with AI, that is not intrusive or manipulative and is tailor made to their needs.


What we are working on
Story
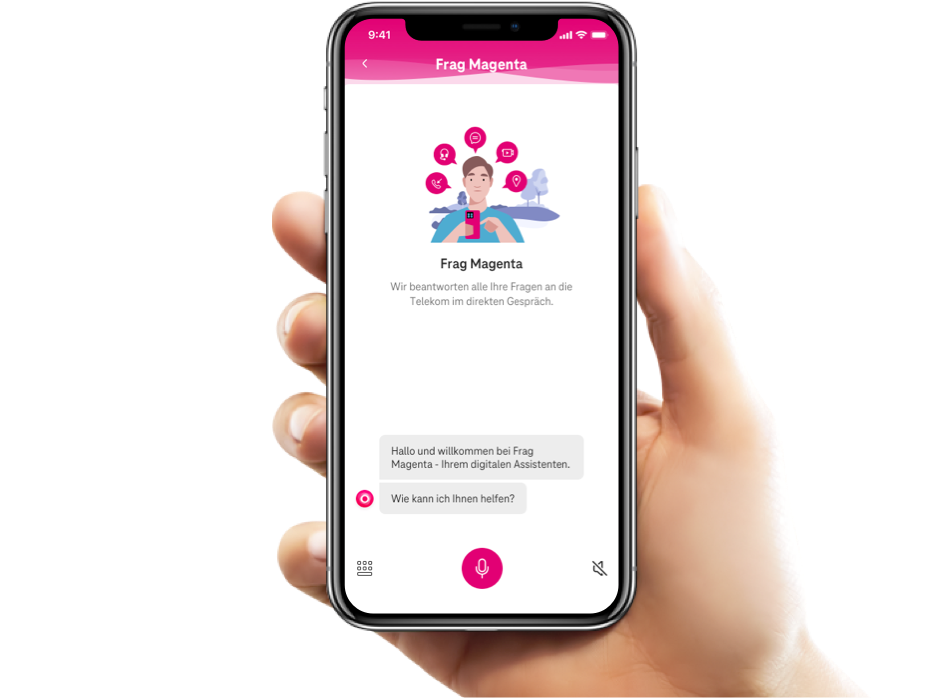
Frag Magenta
We have built and are constantly improving support for our customers with our digital assistant. Human-like, easy-to-access, no-waiting, around-the-clock.

Story
eMpathic
We are buiding Deutsche Telekoms' ‘connected brain’ that individualises customer interactions across all touchpoints and the customer lifecycle.